Florian Jaeger and I recently submitted a research review on “Speech perception and generalization across talkers and accents”, which provides an overview of the critical concepts and debates in this domain of research. The manuscript is still under review, but we wanted to share the current version. Of course, feedback is always welcome.
In this paper, we review the mixture of processes that enable robust understanding of speech across talkers despite the lack of invariance. These processes include (i) automatic pre-speech adjustments of the distribution of energy over acoustic frequencies (normalization); (ii) sensitivity to category-relevant acoustic cues that are invariant across talkers (acoustic invariance); (iii) sensitivity to articulatory/gestural cues, which can be perceived directly (audio-visual integration) or recovered from the acoustic signal (articulatory recovery); (iv) implicit statistical learning of talker-specific properties (adaptation, perceptual recalibration); and (v) the use of past experiences (e.g., specific exemplars) and structured knowledge about pronunciation variation (e.g., patterns of variation that exist across talkers with the same accent) to guide speech perception (exemplar-based recognition, generalization).
While there is substantial compelling evidence for each of these processes, none currently provides a sufficient account of how listeners cope with variability in speech. In our research overview, we highlight the successes and limitations of these various approaches. More importantly, we emphasize overlap and complementarity among lines of research that are often viewed as orthogonal or opposing (e.g., normalization and statistical learning).
In our view, it is the integration of these various processes that is the big open question in research on speech perception. Integrating these accounts is by no means trivial, as evidenced by the on-going debate in speech perception concerning normalization, exemplar-based and statistical learning accounts. However, we believe that reexamining the basic assumptions that underlie these accounts will help point the way forward.
For example, consider normalization. Normalization is often conceptualized as an automatic low-level process that stems from basic aspects of the auditory perceptual system and hence does not involve learning. Historically, one of the major successes of the normalization approach to speech perception is accounting for how listeners cope with variability due to vocal tract differences across talkers: e.g., interpreting category-relevant acoustic cues (such as \(F_1\) and \(F_2\) for vowels) with respect to acoustic cues that provide an estimate of the talker’s vocal tract characteristics (e.g., \(F_0\) and \(F_3\); see Figure 1). The basic ability to interpret speech cues in relation to one another (e.g., \(F_1\) relative to \(F_3\)) might stem from biologically-determined aspects of the auditory system. However, the use of specific cues like \(F_0\) and \(F_3\) as the basis for normalization might stem from statistical learning during early development about the relationship between a talker’s vocal tract size and corresponding vocal tract resonances.
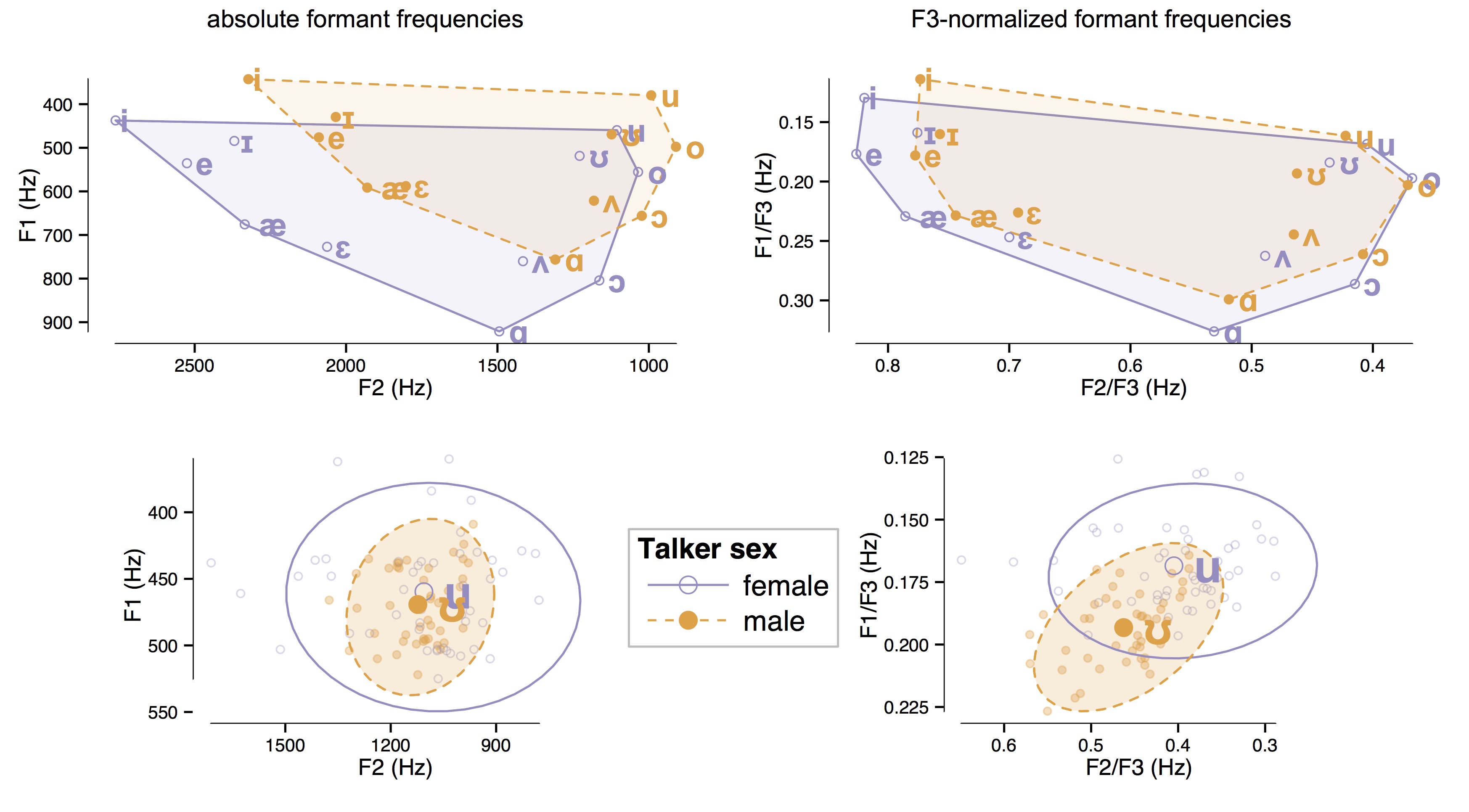
In other words, low-level normalization might be the outcome of statistical learning. If so, this would enable us to situate a wide range of perceptual phenomena along a continuum of statistical learning that operates at various time scales and at various levels of granularity. Phenomena like talker-specific phonetic recalibration (i.e., fine-tuning phonetic category boundaries according to talker-specific cue distributions) are situated at one end of the continuum — as these adjustments occur continuously in response to the statistics of the ambient environment. Phenomena like vocal tract normalization might form the other end of the continuum — as listeners (in principle) only need to learn once, presumably during early development, about how the size and the shape of the vocal tract affect the distribution of energy at certain frequency ranges. Presumably (and speculatively), if the statistical patterns are sufficiently robust across talkers (e.g., the relationship between vocal tract characteristics and \(F_0\) or \(F_3\)), then it would be beneficial (i.e., efficient) for the speech perception system to have evolved to adjust for this relationship at an early stage of processing (e.g., automatic low-level “normalization”). For statistical patterns that are specific to particular talkers or groups, perhaps the relevant perceptual adjustments occur at a later stage of processing (e.g., the mapping of percepts to higher-level categories).
This emphasis on statistical learning might also provide traction in the debate between normalization and exemplar-based accounts of speech perception. As has been discussed extensively in the literature, one of the primary criticisms of normalization accounts is that fine stimulus details are not “filtered out” during perception — as often implicitly or explicitly assumed in normalization proposals — but rather these details are encoded in memory and influence subsequent processing. In turn, one criticism of exemplar-based approaches is that they do not provide a straight forward account for some of the most compelling evidence of low-level normalization: i.e., that speech sounds are interpreted relative to frequency information in the surrounding context, even when this “context” is non-speech sine-wave tones (see work by Holt and colleagues).
These criticisms indicate that neither normalization nor exemplar-based accounts are sufficient. Perhaps these accounts are not contradictory, but rather form part of a complex speech perception system that is capable of statistical learning at various time scales and levels of granularity. Statistical learning in speech involves pattern abstraction over a distribution of speech episodes. Thus, if both talker normalization (i.e., sensitivity to talker invariant information) and talker-specific speech perception can be conceptualized as the result of statistical learning (potentially at different time scales), then there is no debate about the storage of episodic information. Rather, the central questions concern how the learning is implemented and the conditions under which learning leads to low-level versus higher-level adjustments in how speech stimuli are perceived.
comments powered by Disqus